
As technology improves, it is very important to have systems that can get data quickly and reliably. Data virtualization is a new idea that helps companies bring data together from different sources without moving or copying the data between different databases.
This approach allows businesses to create valuable insights from their existing infrastructure investments while streamlining processes and improving operational efficiency. This means businesses can use what they already have to learn more and make things run better.
This blog post will discuss data virtualization, its working, use cases, capabilities, advantages, and limitations.
What is data virtualization?
Data virtualization is a way to bring all the data from different sources together. It’s like a virtual picture, where you don’t need to move the data around. The special middleware or software lets people see and analyze it without moving it.
This process of managing data lets an application get and change data without knowing how it was formatted or where it is stored. It also helps people see all the data about one thing in one place.
How does data virtualization work?
Data virtualization is a way to quickly get data from different places like the internet, cloud, big data sources, and IoT systems. It puts all the data in one place so it can be analyzed.
This technology makes it faster to get the information you need, and it costs less too. There are many Data Virtualization Software available to make your work easy.

Enables user to access the data
Data virtualization software is a program that lets people access data from different sources in one place. The user does not need to know where the data is stored or how it works, only that they can get all the data they need from one spot.
Data virtualization software manages data
Data virtualization software platforms can be used in many ways. It can help people manage data and make creating apps that use data easier.
Better business insights
It takes control of the organization’s data sources with suitable data virtualization software. Limit or grant easy access and locate a single source of truth(SSOT) for all stakeholders in the most cost-effective way possible. Hence the organization can have better business insights.
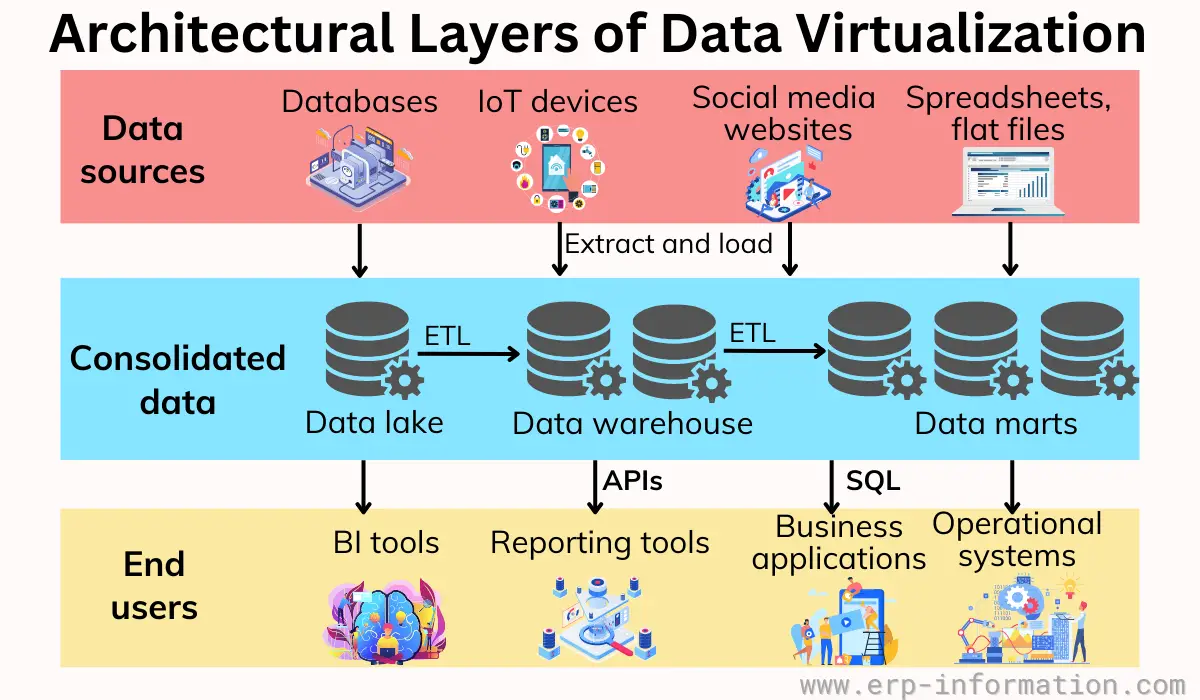
Architectural layers of data virtualization
The architecture of data virtualization has three parts:
- Connection layer: These are connectors to the data source;
- Abstraction layer: This changes the data into something easier to understand and use; and
- Consumption layer: This includes tools that request abstracted data.
The below image shows the details of the layers.
Use cases of data virtualization technology
DevOps
DevOps helps the teams to improve their app-based customer experiences; they may automate most things but leave out the data. By utilizing data virtualization, teams can provide high-quality data to enterprise stakeholders during all application development stages.
Useful to ERP projects
Over half of ERP projects take more time and money than planned. The reason is that it takes a long time and is complicated to set up.
Virtualization can help simplify it, cost less money, and finish the project faster by giving ERP teams virtual copies of data quicker than older methods.
Migration from computer system to cloud
This special technology can help you securely and efficiently move large amounts of data from your current computer system to the cloud. Once that is done, you can practice how the new system works and ensure it is working correctly before fully transitioning over.
Analyzing and reporting
Virtual data copies can create a safe space for testing destructive query and report designs. It lets people safely use the data and get it quickly across different sources for business intelligence projects that require data integration, such as MDM, M&A, and global financial close.
Capabilities of data virtualization
Potential to abstract the technical aspects
Data virtualization is a way to abstract technical information about where data is stored, what type of structure it has, which methods can be used to access it, and what language or technology was used to store it.
Easy data accessibility
This virtualization allows you to connect different data sources and make them available from the same place.
Overall improvisation of data
It helps to effortlessly transform, improve quality, reformat, and aggregate your source data for seamless consumer use.
Adopts data federation
Data federation is an amazing technology that combines result sets from multiple sources, giving you a comprehensive overview of your data.
Data delivery
Its data delivery lets publish the result sets as views and data services that can be executed by users or client applications on demand. It helps to discover the full potential of your data.
Advantages
- Increases the business value.
- Does business analytics.
- Better business insight.
- It is a cheaper option than building a separate store.
- It costs less and collects data from many resources.
- Data are complete, updated, and easily accessible.
- It allows you to get information quickly and right away.
- It enhances data security and governance.
- All the data can be found in one spot. Many people can use this data for many reasons.
- It allows all business users to make reports and analyze data without worrying about the format or where it is stored.
Limitations
- The virtualization server is a way to access all data sources in one place. But if the server has a problem, it can leave all the systems without any data. This means that the server is a single point of failure.
- Its integration technique is different from ETL (Extract, transform Load). It does not help move large amounts of data, like if a financial firm has to process lots of weekly transactions.
- Operational systems might be slow if they are not built to handle extra user queries.
- It can slow down work if the systems don’t have enough power or haven’t been adjusted.
- A Governance approach is needed to budget when it comes to shared services.
- It is not good for taking a picture of data from the past. A data warehouse is better for this.
FAQs
What is the difference between Data Virtualization and Data Federation?
Data federation is a type of data virtualization. Data virtualization helps make different data sources work together, and data federation turns several small collections of data into one larger collection.
What is the difference between Data Virtualization and ETL (Extract, transform Load)?
Data virtualization means that the original data stays where it is, and queries are sent to the source system. ETL copies the data from the source system and saves it in a different place.
Conclusion
From the discussion of this blog post, it can be said that data virtualization is a promising technology that provides organizations with resourceful insights from enterprise data.
This enables enterprises to perform faster and better data analysis, enhancing business decisions.
However, when using this technology, organizations should consider the fact that there may be some costs associated with data security, latency, scalability, etc.
In addition, when deploying data virtualization architecture into an existing IT landscape, organizations must also keep in mind its architecture layers and components, such as adapters, connectors, query transformation engines, etc.