
Delta Lake provides an open-source storage framework to create a unified data lakehouse with various compute engines and programming language APIs, allowing you to build robust applications in Scala, Java, Rust, Ruby, and Python.
This blog post will provide you with the complete details of Delta Lake, its features, capabilities, implementation, storage system, and pros and cons.
New Version: Delta Lake 3.1.0
As of March 2024
More about Delta Lake
A reliable, secure storage layer that enhances the performance of any data lake. This innovative technology ensures ACID transactions remain intact while unifying Streaming and batch data processing capabilities for maximum scalability – an invaluable resource for cutting-edge analytics teams.
How does Delta Lake works?
- It allows organizations to gain insights and make decisions in an instant.
- Enables invaluable business intelligence and insights that can propel future success.
- It uses versioned Parquet files to store the data.
- Apache Spark API can be used to read and write Delta Lake.
- Its table can be copied to any other location.
- Delta Lake adds extra security and management to an open storage environment for all data types, including streaming and batch operations from a single source.
Features
Versatility
Delta Lake empowers users with the convenience of leveraging a unified analytics engine to unlock powerful and flexible operations.
It provides incredible data exploration and manipulation versatility through its use of Apache Parquet, an open-source format.
ACID transaction
With Delta Lake, Big Data workloads are now armed with powerful ACID-compliance capabilities that ensure data accuracy and integrity at every stage.
All changes to the dataset get stored in a secure transaction log, so nothing gets lost along the way. It’s like having an automated audit trail for your most important information.
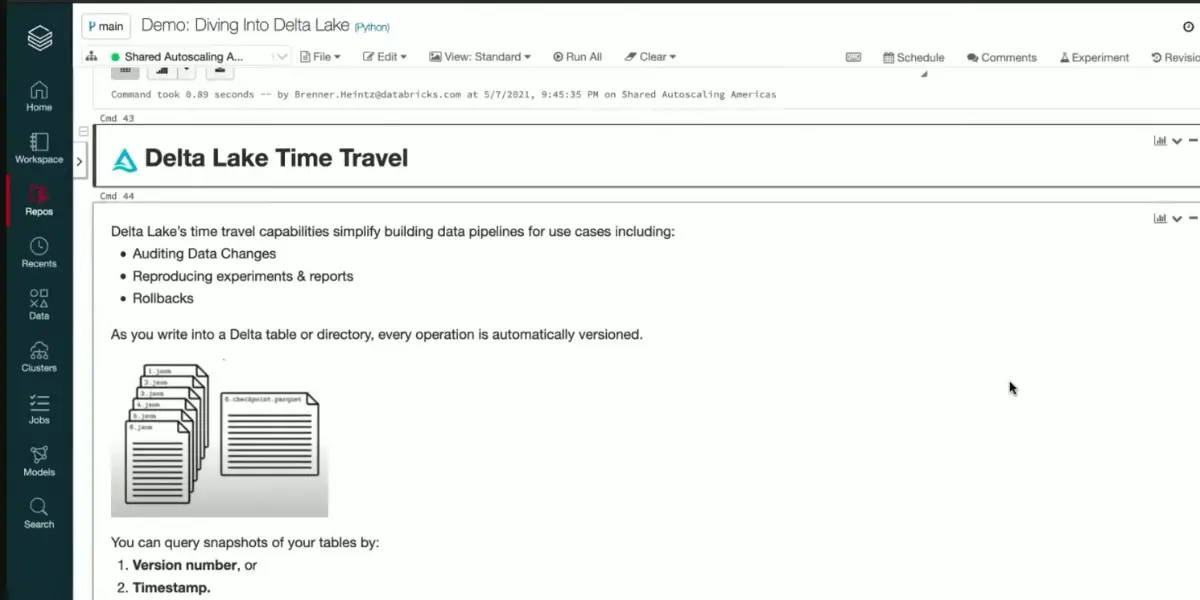
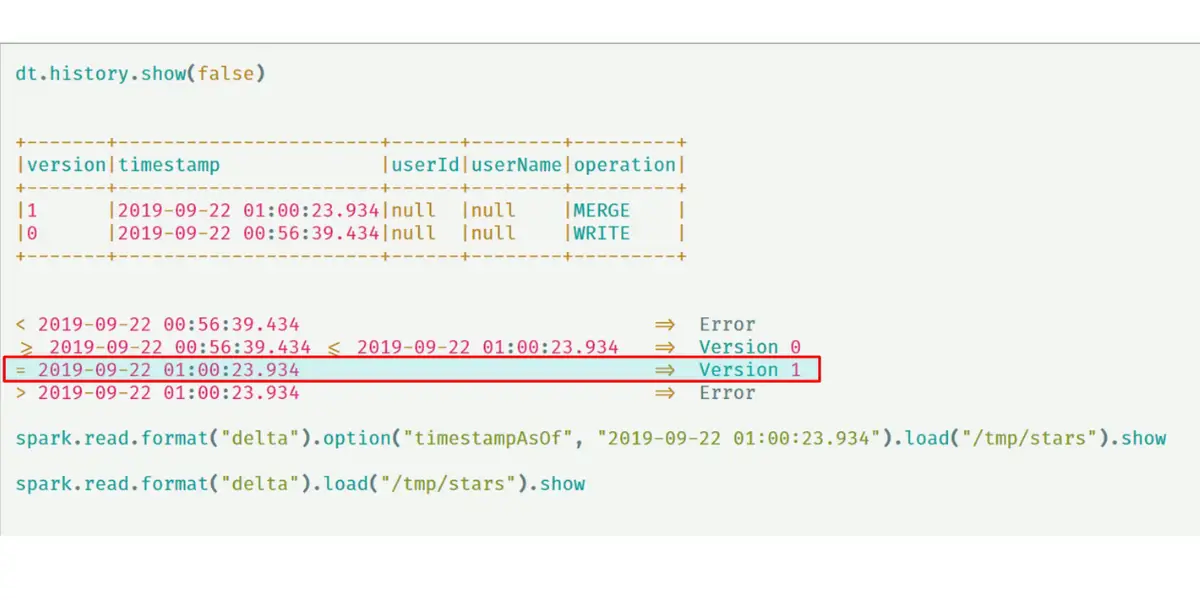
Time travel
This software brings time travel into data science. Its transaction log provides an exact timeline for any changes made to a dataset, making it possible to restore past states and ensure complete reproducibility in experiments and reporting.
Type-checking protocol and schema enforcement
It ensures that your data remains reliable, shielding you from the potentially disastrous effects of bad or corrupted information.
It confidently keeps quality front and center in critical power processes through robust schema enforcement and rigorous type-checking protocols.
Supports data manipulation language
This software enables compliance and complex workflows, like streaming upserts, change-data capture operations, slowly changing dimensions, and beyond. By keeping data manipulation language (DML) commands such as merge update or delete – the possibilities are endless.
Some screenshots of Delta Lake features
Delta Lake version
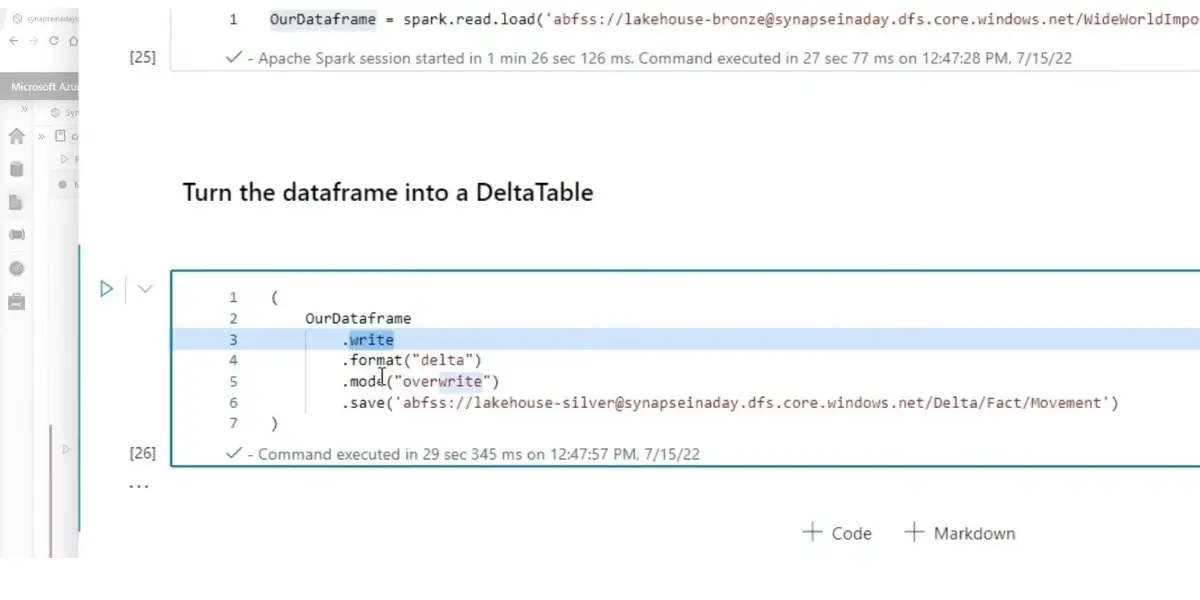
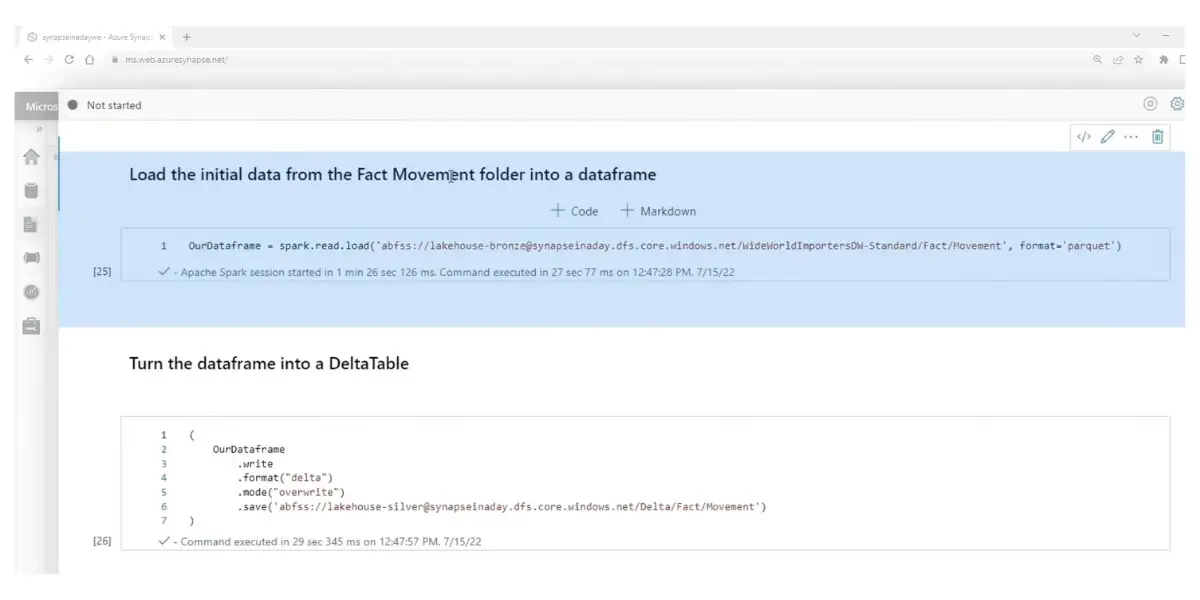
Dataframe view
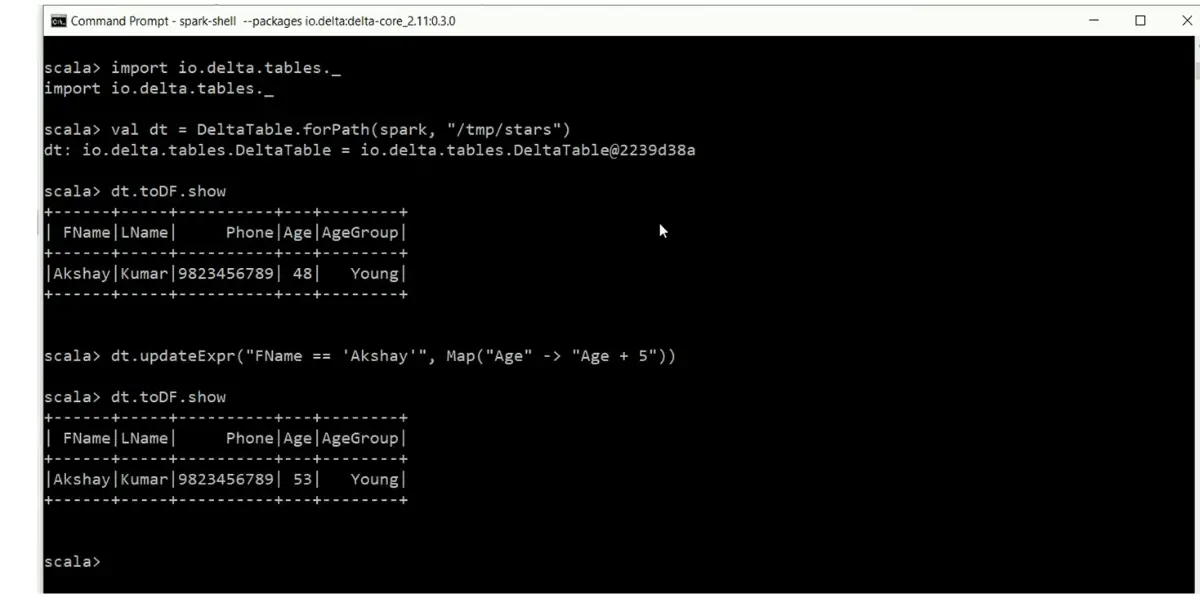
Time travel page view
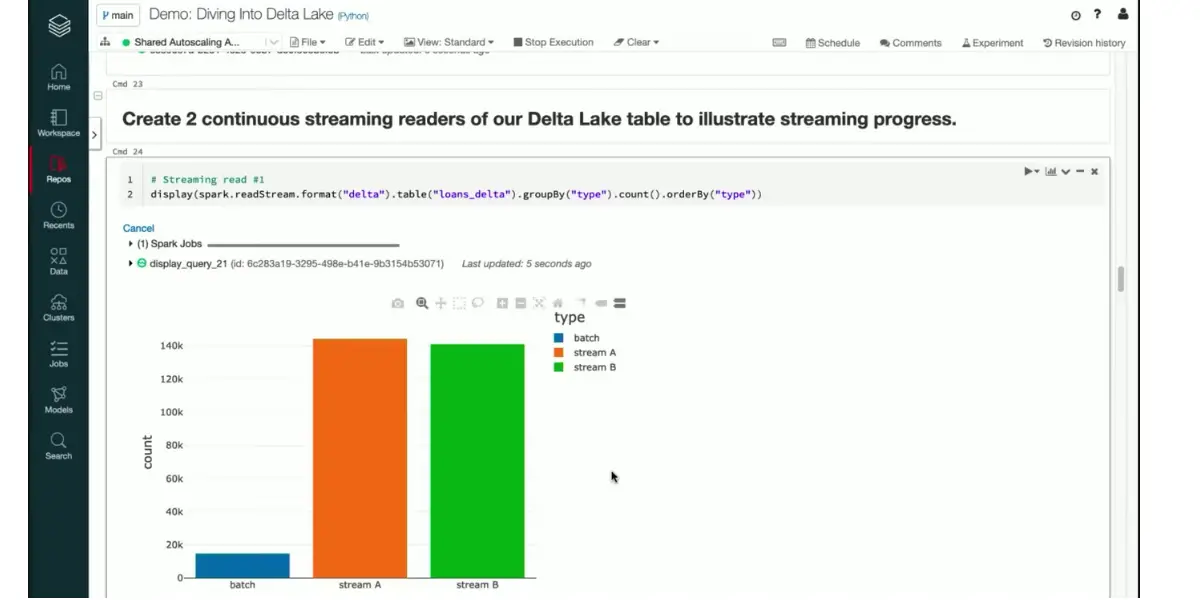
Streaming progress view
Import table
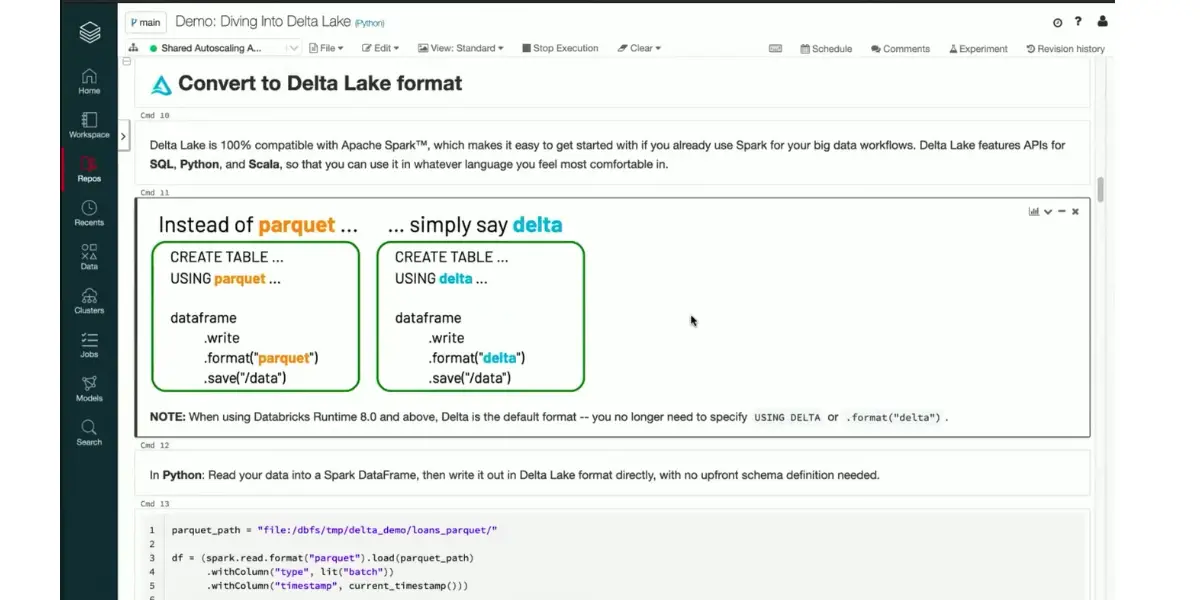
Convert format
Cheat sheet view
Overview of the demo page
Capabilities
Below are the points that will help you understand Delta Lake’s expertise.
- Set up Apache spark, prerequisite setup with Java, set up with interactive shell and set up with a project.
- Table creation: You can easily craft a Delta table by altering your Spark SQL code! Switch out the format from popular sources such as parquet, csv, and JSON to ensure it’s ready for delta.
- Read data: Access all the information in your Delta table by indicating where to find it – no tedious searches are required.
- Updating the table: Delta Lake revolutionizes how tables are modified – this batch job demonstrates the power of using DataFrame APIs to overwrite existing data in a table easily.
- Read older versions of data using time travel: If you’re curious to see what your Delta table looked like before that last data update, then time travel is the perfect solution. Just use the versions option and access a snapshot of your table from its original state – so you can still explore its past no matter how much it’s changed since then.
- Write a data stream to a table: You can write to a Delta table using Structured Streaming. This means the Delta Lake transaction log guarantees that your data will be processed exactly once, even when other streams or batch queries run simultaneously.
- Read a list of changes from a table: Structured Streaming gives you the ultimate flexibility when working with Delta tables – while your stream writes data, you can also access that table for readings. In addition, allowing users to select either a specific version or timestamp to begin streaming ensures up-to-date results and optimized usage of resources.
Streams flow effortlessly in append mode, growing your table with new records. Even while the stream runs, you can access it and read its contents using well-known commands. You can stop the stream by running the stream. Stop () in the same terminal where you started it.
Implementation
Apache Spark and many other providers provide an interactive environment to experience the power of Delta Lake – all you need is a local installation. Immerse yourself in data-driven solutions and explore endless possibilities with your next project.
Then, depending on whether you want to use python or scala, you can set up PySpark or the Spark shell, respectively.
Storage system
The Delta Lake ACID guarantees rely on the atomicity and durability guarantees of the storage system. This means that Delta Lake relies on the following factors when interacting with storage systems:
Automic visibility
Atoms can choose between living in full view or staying hidden – and this principle also applies to files. There is no middle ground with atomic visibility: a file can be seen entirely or not.
Mutual exclusion
A mutual exclusion means only one person can create a file at the final destination.
Consistent listing
If a file has been written in a directory, all future listings for that directory must include that file.
A storage system with built-in support
This software uses the ‘path’ scheme (for example, s3a in s3a://path) to figure out which storage system to use. It will then use the corresponding LogStore implementation that provides guarantees around transactions.
Other storage systems
It allows you to make multiple reads simultaneously, no matter your storage system. And for added safety when making edits, the two cases offer different levels of transactional guarantees depending on the FileSystem implementation.
Delta Lake integration
- Apache Spark
- Apache Flink
- Apache Hive
- Delta Rust API
- Delta standalone
- Apache Pulsar
- SQL Delta import
- Trino
Pros and cons of Delta lake
 Pros
Pros
- It provides Snapshot isolation to read and write data
- Capability to efficiently insert, update and delete
 Cons
Cons
- This software requires more redundant data to support transactions and versioning.
- Security may be a concern when considering adopting it.
- Many queries take longer than expected due to the large datasets stored init.
Conclusion
Delta Lake is a powerful storage platform that enables organizations to store and manage large amounts of data easily. In addition, it provides enterprises with the tools to process and analyze data to derive meaningful insight effectively.
This is an open-source platform, making it easily accessible and customizable for any organization. We hope this blog post is beneficial to you!
Reference