
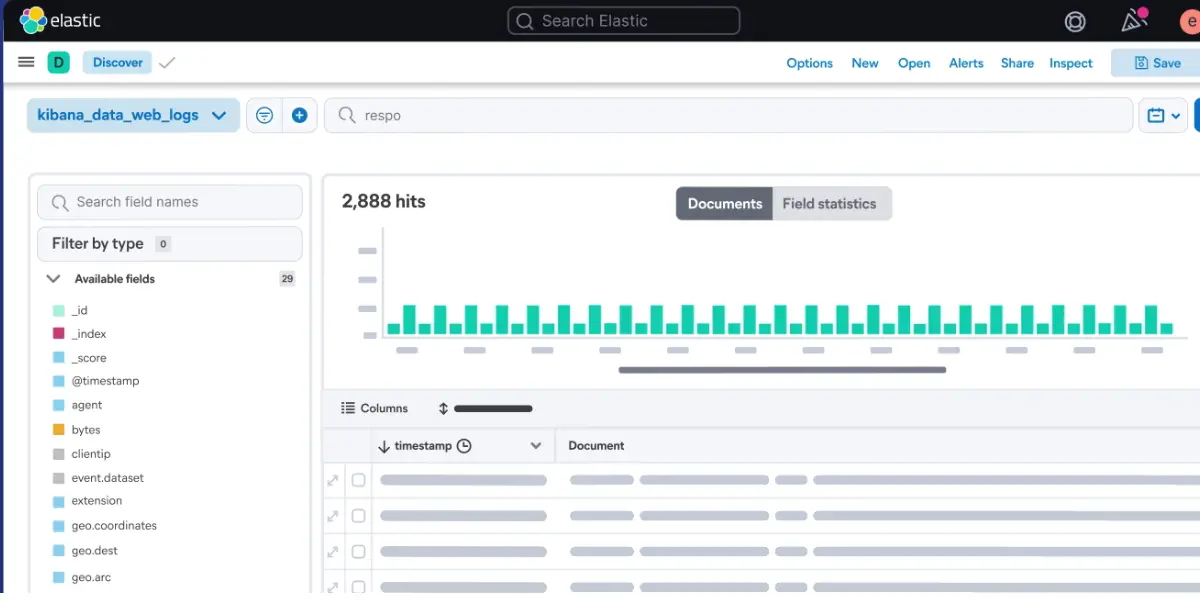
Elasticsearch is a search and analytics engine that anyone can use. It is flexible and scalable. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents.
Leveraging the power of Apache Lucene TM, it’s simple to set up and scale. In addition, it allows users to store and retrieve data at any time.
With its powerful query language, efficient storage architecture, and advanced search functionalities such as aggregations is possible. Elasticsearch is ideal for applications looking for real-time searches in large datasets.
This blog post will help you understand everything you need about elasticsearch, including its uses, architecture, pricing, pros, and cons.
More about Elasticsearch
Elasticsearch lets you store, find, and study a lot of data. This makes the Elasticsearch a good choice for different uses, like system observability, security (threat hunting and prevention), enterprise search, and more.
Because it is so flexible, it is important to design your deployment’s data storage to handle a lot of data.
Categories
The data you store in Elasticsearch will fall into two categories. First, they are content and time series data.
Content
The content of a search is a collection of items, like a catalog of products. The content might be updated often but still has the same value. You should be able to find things quickly, no matter how old they are.
Time series data
Time series data is generated continuously and has timestamps. This data accumulates over time, so you must find ways to store it in a manageable space. As the data gets older, it becomes less important, and people will want to access it less often.
So you can move it to storage that is not as good or fast, but it doesn’t matter as much because people will use it less. For your oldest data, all you need is to be able to access the data. It’s okay if queries take longer to complete.
How does Elasticsearch Work in Data Management?
- Elasticsearch allows you to create multiple layers or “tiers” of data nodes, each with different performance levels.
- Index lifecycle management (ILM) automatically moves indices between different data tiers according to your performance needs and retention policies.
- It stores pictures of your older search results in a remote repository. This will help you save money and keep good performance while searching.
- It searches for data stored on slower hardware at the same time.
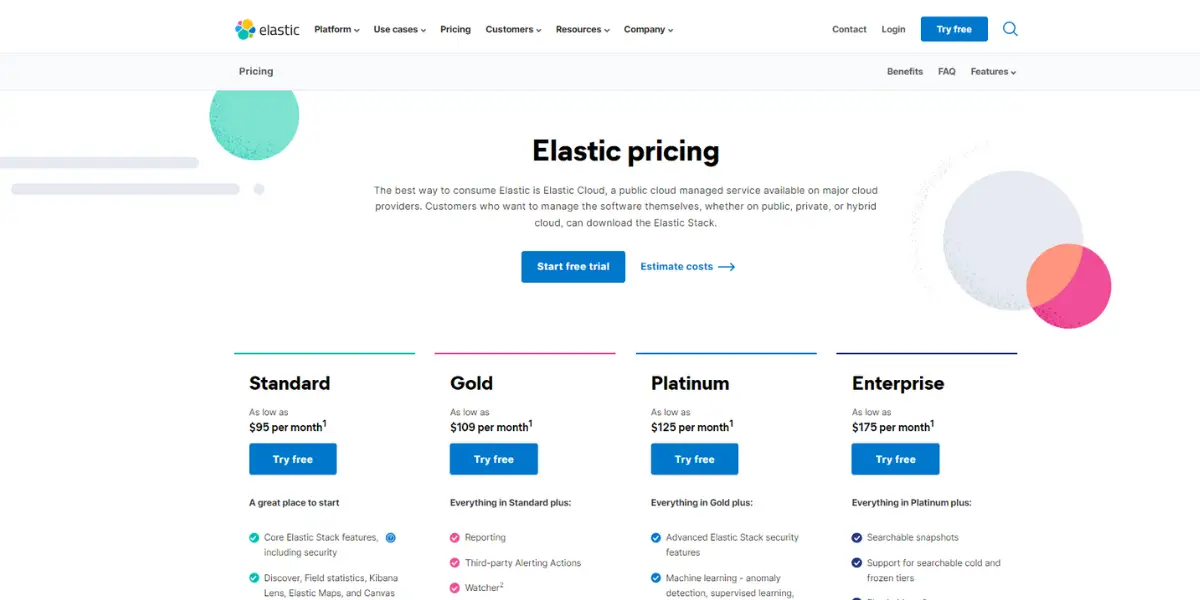
Elastic Pricing
Below are the three elastic pricing plans. Each plan has a free trial.
- Standard: $95/month
- Gold:$109/month
- Platinum:$125/month
- Enterprise:$175/month
Uses of Elasticsearch
The uses of Elasticsearch in different sectors are explained below.
Enterprise search
The gold standard for enterprise search. Elasticsearch is a sophisticated, open search platform that can be used for database search, enterprise system offloading, e-commerce, customer support, workplace content, websites, or any application.
Observability
Your data can be used to help you see what is happening. Use the most widely used observability solution to get information from different sources. This will help you understand what is happening and take action based on what you see.
Security
Elastic provides security teams with the tools to prevent, detect, and respond to attacks on their organization.
Elastic cloud
Elastic cloud is a good way to use all of Elastic’s products with any cloud. You can easily deploy it in your favorite public cloud or multiple clouds.
You can also extend the value of Elastic with cloud-native features. For example, with Elastic Cloud, you can accelerate results that matter securely and at scale.
Elastic stack
The ELK Stack is a set of tools for managing data. It includes Elasticsearch, Kibana, Beats, and Logstash. It can take data from any source and format, search it, analyze it, and visualize it.
Elasticsearch Architecture
The options for storing data with Elasticsearch are listed below. We will go into in-depth detail about the advantages and disadvantages of each option, as well as what to expect regarding data loss, performance, and downtime.
RAID 0
RAID has been a way to combine multiple disks for a long time. RAID has three parts: mirroring, striping, and parity. Each number in RAID means a different combination of these parts.
Performance and capacity
If you have a lot of disks in an array, it will improve read/write performance because the disks can write in parallel. The number of disks in an array affects the read/write speed. For example, if you have five disks in a RAID 0 array, you would have ~5x read/write speed.
Recovery
It offers no recovery, so Elasticsearch must use snapshots or replicas instead. Depending on the size of the disks and how the data is copied onto the array, this can take a long time. In addition, during the recovery step, network traffic and other nodes’ performance will be impacted.
Caveats
Elasticsearch indexes are made up of many shards. If a shard on a RAID 0 volume suffers a disk failure, the index can become corrupted if there are no other replicas. This will result in permanent data loss unless you have snapshot lifecycle management (SLM) to manage backups or have configured Elasticsearch to create replicas.
RAID 1
Performance and capacity
RAID 1 writes the same data to another disk. This creates a copy of the data. Most RAID implementations don’t use the two disks to read simultaneously, so read and write performance is halved. You lose half of your capacity when you write data to both disks.
Recovery
RAID 1 is a system that copies data from one to another k so that if one disk fails, the data is still available on the other k. When you have a lot of disks that store the same data, it makes the disks slow, and there is not enough space. If one disk breaks, you can replace it, and the data will be copied onto the new disk.
Caveats
Most of the time, RAID 1 is used with RAID 0. This is because RAID 1 only supports two disks. So if you need to use more than two disks, you would pair multiple RAID 1 volumes to a striped RAID 0. This is called RAID 10. And it’s used when you have four or more disks.
Doing this gives you some of the performance benefits of using RAID 0 while also having the redundancy of RAID 1. The performance of a RAID 10 system depends on how many disks are in an array. For example, if you have an 8-disk array, the performance would be Nx/2 or 4x.
RAID 5,6
Performance and capacity
Parity allows computers to fix missing data due to a disk failure. Parity means that data is protected from being lost. If some of the data is lost, it can be recovered. But this costs extra money. RAID 5 uses one disk worth of capacity for parity, and RA11144467890““cvbnm,./ID 6 uses two disks.
Recovery
A rebuild occurs when a new disk is added to the array, replacing a former disk. Adding more disks for spinning media is better than increasing disk capacity. However, this will increase read and write times and rebuild times. For SSDs, you must see if higher-capacity disks have faster read and write performances.
Many higher-capacity SSD disks do have higher read/write performance. Using higher-capacity disks will help with read/write performance if this is the case. RAID 5 may suffer one disk failure before any data from the array is lost. RAID 6 can suffer two disk failures without losing any data.
Caveats
RAID 5 and 6 can both handle disk failure, but it’s not without cost. For RAID 5, this means you’re just as vulnerable as in RAID 0 until you add a new disk. Unfortunately, if another disk fails, all data on the array will be gone, and you’ll have to recover it from other sources.
Multiple data paths
Elasticsearch has a setting called path. Data is used to configuring the filesystem location(s) for Elasticsearch data files.
When a list is specified for the path and data, Elasticsearch will use multiple locations for storing data files. This can be useful for storing your data files in multiple places for redundancy or performance reasons.
Performance and capacity
Elasticsearch stores data in shards and each shard is written to a data path with the freest space. Therefore, if one shard gets most of the writes, then performance is limited to the speed of one data path.
MDP does not create copies or backups of data (mirroring or parity), which means that all capacity on all disks can be used for data storage.
Adding a new data path to a node that already has data stored on other paths can lead to hot-spotting of the new disk since Elasticsearch won’t balance shards between data paths. So instead, all new shards will be sent to the new path because it has the freest space.
Recovery
Disks will go bad. This means that the data on them can’t be accessed anymore. Removing the data path from the Elasticsearch node configuration is important if this happens. Here’s how:
- Disable shard allocation.
- Stop the node.
- Remove the bad data path from the Elasticsearch config file.
- Restart the node.
- Re-enable shard allocation
Caveats
If a device specified in multiple data paths dies, the path is ignored for the next shard allocation. However, subsequent rounds will consider the path eligible for shard allocations again.
Elasticsearch handles watermarks on a per-node basis. This means that if one data path hits the high watermark, the entire node will hit the high watermark.
Comparison Table
This table compares RAID 0, RAID 1, RAID 5&6, and multiple data paths.
| Architectures | Pros | Cons |
| RAID 0 | * Easy to setup * High performance * High Capacity * Elasticsearch considers the array to be one large disk | * If one of the disks in the array fails, then all of the data on the array is lost, not just the data on the single disk * The cluster must copy replica shards to a new array to recover, which will require a lot of resources and time * If there are no replica shards, then there is a potential for data to be permanently lost |
| RAID1 | * High data protection * Easy recovery when a disk fails * It Sees the array in a single disk | * low capacity, take 50% of your disk * Less efficient in reading and writing * Covers only two disks |
| RAID 5,6 | * Medium data protection * Easy recovery when the disc fails * Medium to high performance and capacity * Elastic sees the array as a single | * Capacity loss due to parity * RAID 5 can suffer single and RAID 6 can suffer two disc failures * Restoring the disc takes more than 24 hours * There is a risk of total data loss in restoring * Restore may reduce read and write performance |
| Multiple data paths | * Easy to setup * Able to add disk at anytime * High utilization of disc capacity | * No balance between the data path * If a single data store affects the whole watermark node will be affected * The disk cannot be hot swapped * Adding a disk can lead to overloading the disc |
Industrial supports
- Public sector
- Health care
- Technology
- Financial services
- Telecommunication
- Retail and e-commerce
- Manufacturing and Automotive
Conclusion
Elasticsearch is an analytics engine that helps developers create powerful, scalable application solutions. It can quickly index large amounts of data with an intuitive search query language that makes it easy to retrieve information.
Its flexible distributed architecture ensures high availability and scalability, and its advanced features, such as aggregations, provide a wealth of capabilities for powerful analytics.
By utilizing Elasticsearch, applications can tap into a powerful platform that enables real-time Search in large datasets with minimal effort.