
A large scale data storage systems are a powerful tool for managing vast amounts of data. It offers reliable and secure storage solutions, allowing organizations to store and access massive amounts of information on shared file systems.
Large scale data storage systems allow for automated backups, disaster recovery strategies, and secure access control.
They also provide scalability, performance optimization, and integration with other applications. By leveraging these features, businesses can ensure their data is stored efficiently and accessed quickly when needed.
This blog post will provide details of the best large scale data storage systems with their features, pricing, and likes and dislikes.
More details about large scale data storage system
Large scale data storage collects, manages, and analyzes massive datasets in real-time to generate valuable insights for better decision-making.
An innovative large scale data storage system utilizes a network of numerous commodity servers and high-capacity disks, leveraging Massively Parallel Processing to power analytic software capable of digesting massive quantities of information.
Assembled from various sources, the combined components provide an efficient means for working with complex datasets.
List of 10 best large scale data storage systems
1. Elasticsearch
Elasticsearch is one of the best large-scale data storage systems. It enables you to easily access and analyze any data of any size, shape, or form. With its distributed structure and restful search abilities, this powerful engine centralizes your information for effortless exploration.
Features
- Scalability and resiliency
- Data storage
- Stack security
- Deployment
- Data management
- Stack monitoring
- Ingest and enrich
- Search and analyze
- Explore and visualize
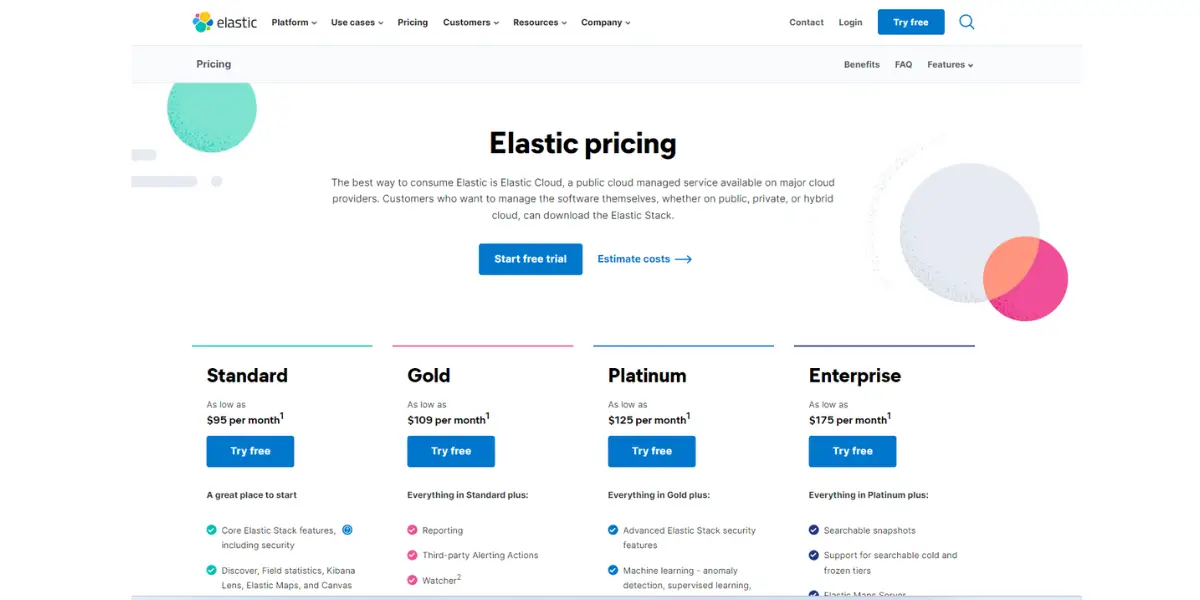
Pricing
A free trial is available for all the plans.
- Standard: $95 per month
- Gold: $109 per month
- Platinum: $125 per month
- Enterprise: $175 per month
Likes
- Extremely fast search and filtering on a large database
- This is a powerful aggregation that can allow many customizable analytics and reports
- Great database, scalability, and deployment
- Text-based searches on data
- Machine learning for anomaly detection
- Aggregations allow progressive add search criteria to refine their searches.
Dislikes
- It does not have multi-language support
- Some users felt that documentation, the ability to update or change existing live field mappings, could be better.
Other details
| Deployment | Cloud, SaaS, Web-Based |
| Support | 24/7 (Live Rep), Chat |
| Training | In-Person, Live Online, Webinars, Documentation |
| Customer Rating | Capterra: 5.0 out of 5 (1+reviews) |
User opinion
Overall Elastic empowers your team to take quick and decisive action against cyber threats, ensuring minimal disruption while quickly finding the source of any issues. Elevate security with Elastic’s proactive approach to protect, detect and respond efficiently.
2. MongoDB
MongoDB helps thousands of organizations manage their data – from some of the world’s most successful companies to the smallest startups.
Operated on over 1000 clusters, MongoDB has powered millions of operations per second on more than 100 billion documents and petabytes worth of information.
Its scalability has three metrics: Cluster scale, performance scale, and data scale.
Features
- Database
- Data Search
- Data lake
- Charts
- Dynamic sync
- APIs, Triggers, functions
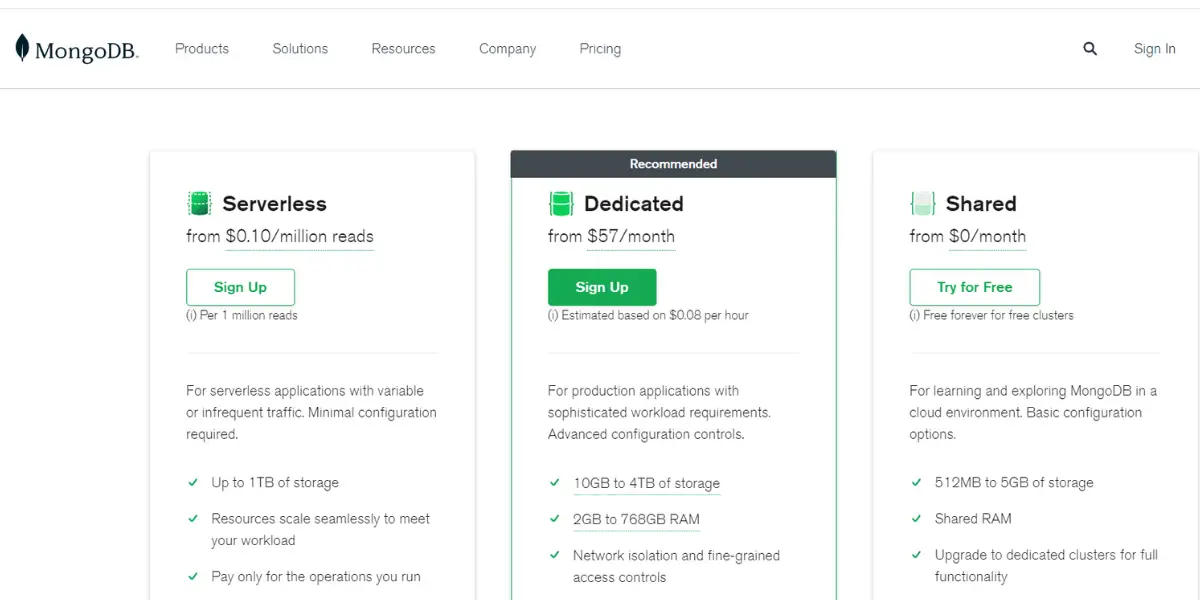
Pricing
- Serverless: $0.10/million reads
- Dedicated: $57/month
- Shared: free
Likes
- High speed and good performance level
- Quick set up and easy environment
- Flexibility, scalability, and sharding
- Good technical support
- Easy documentation
Dislikes
- Limited data size
- Some users felt that Joining MongoDB was a tedious task.
- MongoDB is a fast database that uses indexes to find information quickly. However, MongoDB will be very slow if the indexes are not set up correctly.
- Duplication of data
- It needs a lot of storage due to a lack of joins functionalities.
Supported industries
- Financial Services
- Telecommunications
- Healthcare
- Retail
- Public Sector
- Manufacturing
Other details
| Deployment | Cloud, SaaS, Web-Based |
| Support | Email/Help Desk, FAQs/Forum, Knowledge Base, Phone Support,24/7 (Live Rep), Chat |
| Supported device | Desktop – Mac, Windows, Linux, On-Premise – Windows, Linux |
| Supported Languages | Arabic, Danish, German, English, Persian, Finnish, French, Hungarian, Italian, Japanese, Dutch, Norwegian, Portuguese, Romanian, Russian, Spanish, Swedish, Turkish, Urdu, Chinese (Simplified) |
| Training | In-person, Live Online, Webinars, Documentation, Videos |
| Customer Rating | Capterra: 4.7 out of 5 (413+ reviews) G2: 4. 5 out of 5 (473+ reviews) |
User opinion
MongoDB was created in 2007 and now has a group of developers from all around the world. It has become popular with businesses because it offers features that help companies to achieve their goals.
3. Apache Kafka
Apache Kafka is revolutionizing how companies handle their data, enabling streamlined pipelines and analytics on an unparalleled scale.
Serving thousands of customers worldwide, it drives mission-critical applications with speed and efficiency – transforming how organizations interact with their most valuable asset: information.
Feature
- High throughput
- Scalable
- Payment storage
- High availability
- Client libraries
- Large ecosystem open-source tool
- Massage brokers
- Website activity tracking
- Metrics
- Stream processing
- Event sourcing
- Cimmit log
Price
For pricing details, contact the vendor directly.
Likes
- It offers a low latency value
- High throughput due to low latency
- Durability and real-time handling
- Reduces the need for multiple integrations
Dislikes
- Lack of monitoring tools
- It will not support wildcard topic selection
- Issue of massage tweaking
Other details
| Deployment | Cloud, SaaS, Web-Based |
| Support | Email/Help Desk, FAQs/Forum, Knowledge Base, Phone Support |
| Supported device | Desktop – Mac, Windows, Linux |
| Training | Documentation |
| Customer Rating | Capterra: 4.7 out of 5 (10+reviews) |
User opinion
Kafka is the go-to technology for developers and architects who want to build scalable, real-time data streaming applications. It was designed to help solve the problem of managing continuous data flows. Data engineers tried many different options before deciding to create Kafka. As a result, it can handle billions of messages a day.
4. Delta Lake
Delta Lake Sharing is a new way to share data with other organizations. It is the first open protocol for secure data sharing. This makes it easy to share data with organizations that use different computing platforms.

Features
- Share live data directly
- Support diverse client
- Security and governance
- Scalability
- ACID transactions
- Schema Enforcement
Price
For pricing details, contact the vendor directly.
Likes
- Snapshot isolation
- Easy insertion, deletion, and updation of data
Dislikes
- Delta Lake requires more redundant data to support transactions and versioning.
- Security may be a concern when considering adopting delta lake.
- Many queries take longer than expected due to the large datasets stored in Delta Lake.
User opinion
Delta Lake provides the essential foundation for harnessing the power of data on Databricks Lakehouse Platform, combining open-source software with file-based transaction logs to ensure your stored tables and data remain secure through ACID transactions. It’s a reliable solution that ensures scalability without compromise.
5. Kubernetes
Kubernetes is an open-source system revolutionizing the way containerized applications are deployed and scaled.
It is also known as K8s; with 15 years of experience running production workloads at Google combined with cutting-edge ideas from the community, Kubernetes makes it easier than ever to manage a group of containers that make up your application in one logical unit.
Features
- Cluster architecture
- Services, load balancing, and networking
- Storage and security
- Cluster administration
- Scheduling, preemption, and eviction
- Policies and configuration
Price
You need to contact Kubernetes for pricing details.
Likes
- Improves productivity
- Introduces the concept of GitOps
- Wide community and ecosystem
- Fast growth and future proof
- Universal support
- It can adapt to the usage and maintenance requirements
- Stateful applications
- It is used to construct microservices-based applications
Dislikes
- Steep learning curve
- Need knowledge of cloud-native technologies
- Migrating with existing applications is a little tuff
- Comparatively little expensive
- Initial setup is time-consuming and complex to learn
User opinion
Overall, Kubernetes storage is a system that helps store data. In addition, it can help store different types of data in one place. This is useful for people accessing and using many different data types.
6. ApacheAirflow
Airflow is a platform that lets you develop, schedule, and monitor workflows. Workflows are like a set of instructions for a computer to follow.
They can be simple, like adding two numbers together, or more complex, like processing data from many different sources. The Airflow framework is written in Python and lets you connect to almost any technology.
A web interface also helps you keep track of your workflows and makes it easy to change them if needed.
Feature
- Dynamic pipeline generation
- Extensible to easily adjust
- Flexible
- Pure Python
- Useful UI
- Robust integrations
- Easy to use and open source
Price
Open source system. Many providers and packages are available and integrate with third-party projects.
Likes
- Open source
- Creative workflow and high granularity
- Easy and potential for large data operation
- Dependency management
- Flexible
- Templating and macros
- Many operators for the build pipeline
- Great UI and logs
Dislikes
- The data processing model is not easy to understand for new engineers.
- The CI/CD process is tricky.
- If you want to use Airflow on a Windows computer, you can’t just run it normally. Instead, you have to use Docker to make it work.
- Renaming DAG is required to change the schedule.
Other details
| Deployment | Cloud, SaaS, Web-Based |
| Customer Rating | Capterra: 5 out of 5 (4+reviews) G2: 4.3out of 5 (69+reviews) |
User opinion
Airflow is that which works well with Python. This is important because Python is used extensively for data science, engineering, and design. This makes our work easier, and you can automate more things.
7. Apache Parquet
Parquet is a powerful cooperative tool for data science, engineering, and design professionals. It seamlessly integrates Python into our workflow, allowing us to automate complex tasks easily.
Having direct support for Python makes it easier for us to program and automate tasks.
Feature
- Configurations
- Extensibility
- Metadata
Pricing
Contact the Apache Parquet for pricing details.
Likes
- Low storage consumption
- Files can be compressed
- Data security
Dislikes
- A bit difficult to learn in the initial stage
- Some users expect more schemas for different business solutions
- Difficult to load S3 when files get too big
- Difficult to find supporting libraries
Other details
| Deployment | Cloud, SaaS, Web-Based |
| Support | FAQs/Forum, Knowledge Base |
| Customer Rating | Capterra: 5.0 out of 5 (1+reviews) G2: 4.0 out of 5 (10+reviews) |
User opinion
Overall, Apache Parquet is a powerful columnar storage format for the Hadoop ecosystem that can be used with any data processing framework, model, or language. As a result, it is a versatile solution to store and process big data projects.
8. Microsoft SQL server
With Microsoft Azure’s SQL Server Data Files, you can now create and access databases in any environment, from on-premises to virtual machines.
Plus, transferring data is a breeze as the files are stored securely in cloud-based Blob storage. Streamline your database management processes with this high-performance solution.
Features
- Files and file groups
- System and contained database
- Event notification
- File stream, filetable, and Blob
- SQL Graph
- The sequence number and service broker
Pricing
A free trial is available. Contact Microsoft for pricing details
Likes
- A great tool to leverage data
- Stable and does not consume a lot of resources
- This is an excellent place to find data that the government can use.
- It is cost-effective, reliable, and works well with other systems.
- Security Benefits
- Snapshot backup
Dislikes
- Some users felt that error messages could be confusing and leave you wondering what happened.
- It is frustrating to share templates with other programmers on our team.
Other details
| Deployment | Cloud, SaaS, Web-Based |
| Support | Email/Help Desk, FAQs/Forum, Knowledge Base, Phone Support, 24/7 (Live Rep), Chat |
| Supported device | Desktop – Windows, Linux, n-Premise – Windows, Linux |
| Supported Languages | German, English, French, Italian, Japanese, Korean, Portuguese, Russian, Spanish, Chinese (Simplified) |
| Training | Webinars, Documentation, Videos, In Person |
| Customer Rating | Capterra: 5.0 out of 5 (1+reviews) G2: 5.0 out of 5 (1+reviews) |
User opinion
Overall, SQL Server is a system that helps businesses manage data. This can be used with Azure SQL Database, Azure Cosmos DB, MySQL, and other data environments.
9. Apache Cassandra
Apache Cassandra is a type of NoSQL database that many companies use. It is scalable and can handle a lot of data without compromising performance. It is also fault-tolerant, which means it can handle unexpected events without problems.

Features
- Hybrid
- Fault-tolerant
- Focus on quality
- Scalable
- Elastic
- Performant
- Security and Observability
- Distributed
Pricing
This is a free open source.
Likes
- Continuous data availability
- Cost-effective and low maintenance
- High performance
- Low tolerance
Dislikes
- Users are facing difficulty in moving data from Cassandra to any relational database.
- It does not fit transactional data
- It does not support aggregates
- Database event lagging
Other details
| Deployment | Desktop – Mac, Windows |
| Customer Rating | Capterra: 4.2 out of 5 (31+reviews), G2: 5.0 out of 5 (1+reviews) |
User opinion
Cassandra is a tool that helps manage large amounts of data across multiple data centers or in the cloud. Cassandra offers a solution to manage write-data growth while ensuring greater flexibility, performance, scalability, and reliability.
10. Apache ORC
Apache ORC is a free and open-source large scale data storage systems way to store data for distributed frameworks like Apache Spark, Hive, Flink, and Hadoop. Columnar storage ensures that your big data projects get the maximum efficiency from all of its features.
In addition, it is the smallest and fastest columnar storage for Hadoop workloads.
Features
- ACID support
- Built-in Indexes
- Complex types
Pricing
This is a free, open-source platform.
Likes
- Simple and tiny tool
- Efficient and powerful indexing
- Columnar storage for Hardhoop workloads
- The application has drone analytics features useful for abroad clients
Dislikes
- The tool is not much stable
- Not much user-friendly
- Starting it will take time to learn and little confusing
- The interface is a bit slow
Our opinion
Apache ORC is the quick-read solution for data retrieval. Its well-partitioned and indexed files ensure you can achieve speedy results with precision and accuracy, allowing fast access to queries of all varieties.
Conclusion
The best large-scale data storage systems provide reliable and secure data storage solutions. In addition, they offer scalability, performance optimization, automated backups, and disaster recovery strategies.
By utilizing these features, businesses can ensure their data is stored efficiently and accessed quickly when needed. Such a system will help organizations manage their data comprehensively and cost-effectively while providing maximum security.
We hope our article on large scale data storage systems was more knowledgeable!!